Abstract

With the advent of consumer grade depth sensors, low-cost volumetric capture systems are easier to deploy. Their wider adoption though depends on their usability and by extension on the practicality of spatially aligning multiple sensors. Most existing alignment approaches employ visual patterns, e.g. checkerboards, or markers and require high user involvement and technical knowledge. More user-friendly and easier-to-use approaches rely on markerless methods that exploit geometric patterns of a physical structure. However, current SoA approaches are bounded by restrictions in the placement and the number of sensors. In this work, we improve markerless data-driven correspondence estimation to achieve more robust and flexible multi-sensor spatial alignment. In particular, we incorporate geometric constraints in an end-to-end manner into a typical segmentation based model and bridge the intermediate dense classification task with the targeted pose estimation one. This is accomplished by a soft, differentiable procrustes analysis that regularizes the segmentation and achieves higher extrinsic calibration performance in expanded sensor placement configurations, while being unrestricted by the number of sensors of the volumetric capture system. Our model is experimentally shown to achieve similar results with marker-based methods and outperform the markerless ones, while also being robust to the pose variations of the calibration structure.
Overview
Volumetric Capture
Our volumetric multi-sensor alignment method is integrated in VCL’s Volumetric Capture system and can successfully align multiple heterogeneous sensors (i.e. Intel Realsense D415 and Microsoft Kinect Azure). Information about its use can be found in the corresponding Wiki.
Concept

We use a single volumetric structure easily assembled by commodity packaging boxes to establish correspondences between sensors imaging it from various viewpoints. Our approach is fully geometric using only depth information acquired by each sensor and structurally labelling all boxes sides. Each side’s centroid represents a 3D correspondence with a virtual structure that serves as a global anchor for all views. This enables a quick initial alignment that can be further refined through a global optimization step. Our multi-sensor volumetric alignment method can successfully align multiple (we’ve tested 3 to 16) depth sensors and since our was trained to be sensor agnostic, it can adapt to different sensing technologies and even combine heterogeneous sensor types.
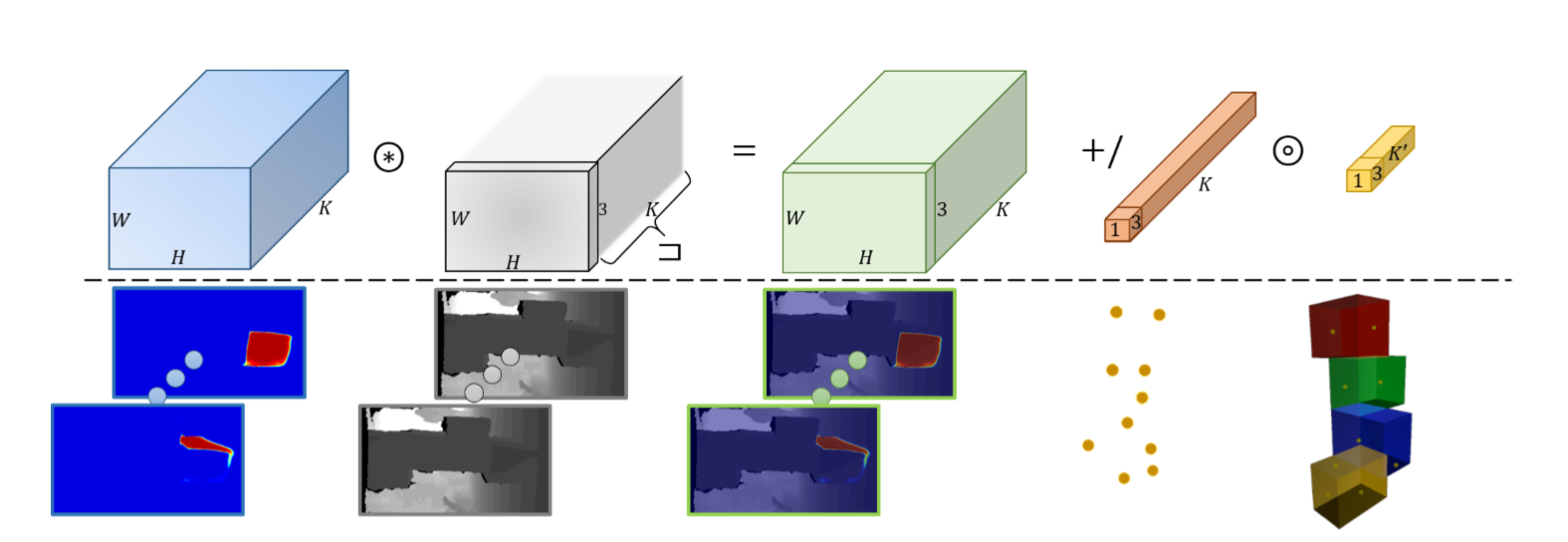 The deep soft Procrustes analysis enables end-to-end geometric supervision for a semantic segmentation model. On the first row, the corresponding tensor operations are depicted. Starting from a light blue W×H×K tensor P containing each of the K classes’ probabilities and the gray 3×W×H vertices tensor V obtained by de-projecting the input depthmap, we establish soft correspondences as follows: i) we multiply the tensors P and V after expanding – or otherwise, broadcasting – V to 3×W×H×K ; ii )the resulting 3×W×H×K light green tensor is reduced via a mean operation across the spatial dimensions W and H, resulting to the orange 3×K tensor C containing the softcorrespondences’ 3D coordinates; iii) after masking with the ground truth labels and performing a SVD operation, the remaining correspondences in the yellow tensor C′ are now aligned and any error function between them can be back-propagated to the semantic segmentation network
The deep soft Procrustes analysis enables end-to-end geometric supervision for a semantic segmentation model. On the first row, the corresponding tensor operations are depicted. Starting from a light blue W×H×K tensor P containing each of the K classes’ probabilities and the gray 3×W×H vertices tensor V obtained by de-projecting the input depthmap, we establish soft correspondences as follows: i) we multiply the tensors P and V after expanding – or otherwise, broadcasting – V to 3×W×H×K ; ii )the resulting 3×W×H×K light green tensor is reduced via a mean operation across the spatial dimensions W and H, resulting to the orange 3×K tensor C containing the softcorrespondences’ 3D coordinates; iii) after masking with the ground truth labels and performing a SVD operation, the remaining correspondences in the yellow tensor C′ are now aligned and any error function between them can be back-propagated to the semantic segmentation network
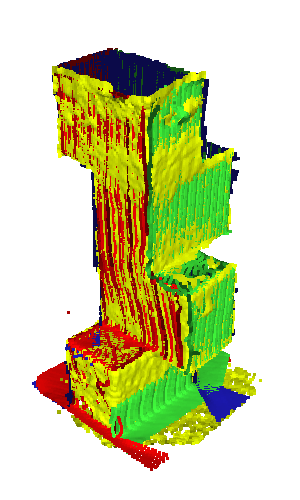
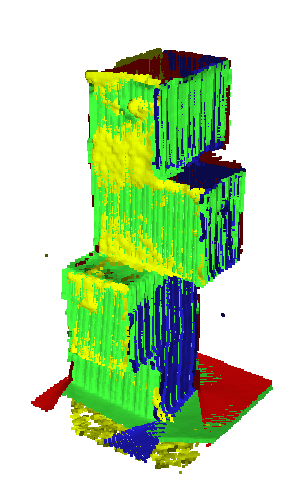
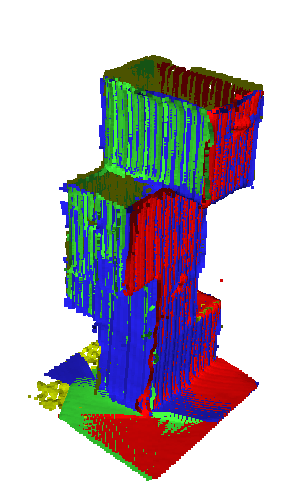
Results

Publication

Authors
Vladimiros Sterzentsenko *, Alexandros Doumanoglou *, Spyridon Thermos, Nikolaos Zioulis, Dimitrios Zarpalas, and Petros Daras
Citation
If you use this code and/or models, please cite the following:
@inproceedings{sterzentsenko2020deepsoftprocrustes,
title={Deep Soft Procrustes for Markerless Volumetric Sensor Alignment},
author={Vladimiros Sterzentsenko and Alexandros Doumanoglou and Spyridon Thermos and Nikolaos Zioulis and and Dimitrios Zarpalas and Petros Daras},
booktitle={2020 IEEE Conference on Virtual Reality and 3D User Interfaces (VR)},
year={2020},
organization={IEEE}
}
Acknowledgements
This project has received funding from the European Union’s Horizon 2020 innovation programme Hyper360 under grant agreement No 761934.
We would like to thank NVIDIA for supporting our research with GPU donations through the NVIDIA GPU Grant Program.



Contact
Please direct any questions related to the code & models to vladster “at” iti “dot” gr or post an issue to the code repo.