
Abstract
Learning based approaches for depth perception are limited by the availability of clean training data. This has led to the utilization of view synthesis as an indirect objective for learning depth estimation using efficient data acquisition procedures. Nonetheless, most research focuses on pinhole based monocular vision, with scarce works presenting results for omnidirectional input. In this work, we explore spherical view synthesis for learning monocular 360o depth in a self-supervised manner and demonstrate its feasibility. Under a purely geometrically derived formulation we present results for horizontal and vertical baselines, as well as for the trinocular case. Further, we show how to better exploit the expressiveness of traditional CNNs when applied to the equirectangular domain in an efficient manner. Finally, given the availability of ground truth depth data, our work is uniquely positioned to compare view synthesis against direct supervision in a consistent and fair manner. The results indicate that alternative research directions might be better suited to enable higher quality depth perception. Our data, models and code are publicly available at our project page.
Overview
Spherical Disparity
We derive our spherical disparity model under a purely geometrical formulation.
Spherical stereo comprises two spherical viewpoints that image their surroundings in their local spherical coordinate system.
These are related via their 3D displacement (i.e. baseline), defined in a global Cartesian coordinate system.


By taking the analytical partial derivatives of the Cartesian to spherical conversion equations, a formulation of spherical angular disparity in terms of the radius (i.e. depth) and the baseline is made.

Considering a horizontal (red, 🔴) stereo setup (i.e. displacement only along the x axis) as well as a vertical (blue, 🔵) stereo setup (i.e. displacement only along the y axis) it is apparent that the former includes both longitudinal as well as latitudinal angular displacements, while the latter one only includes latitudinal, as also illustrated in the following figures.
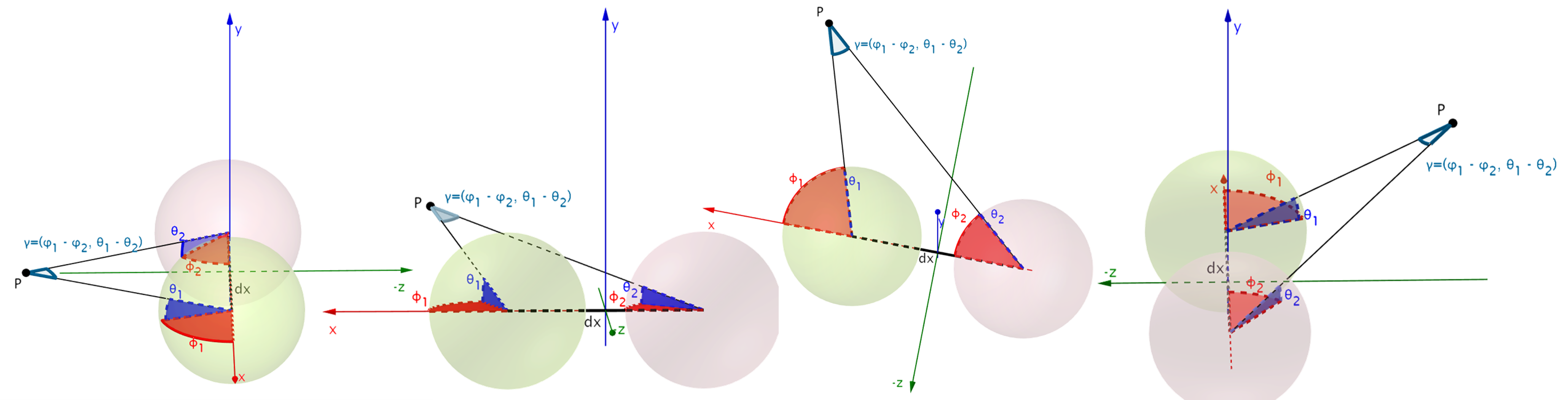
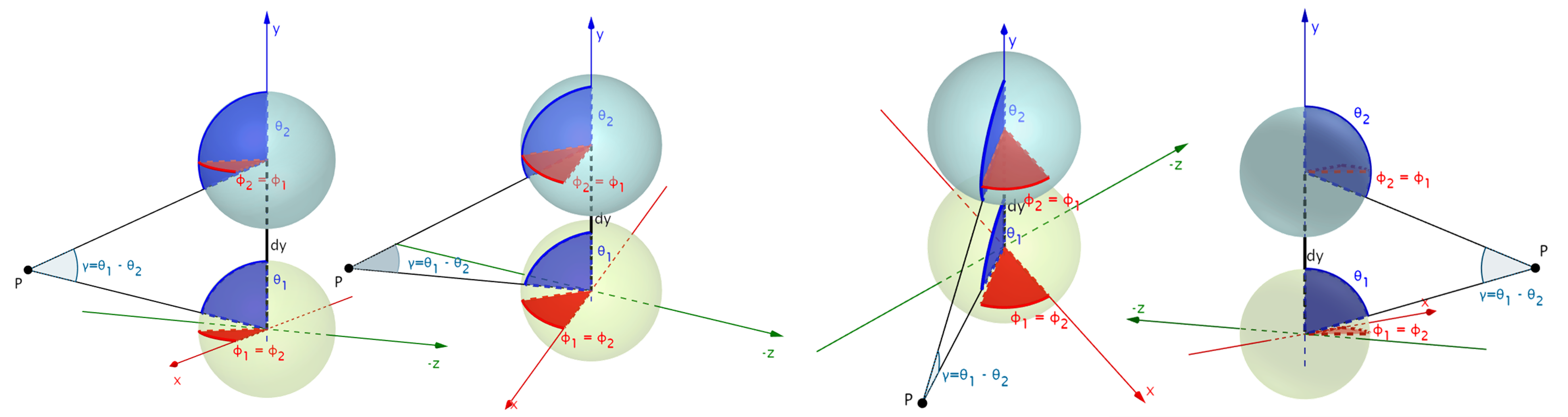
As a result, we can use this depth derived disparity formulation to self-supervise spherical depth estimation. Crucially, for the horizontal case, this is only possible using depth-image-based rendering (DIBR) instead of inverse warping, as it helps in overcoming the irregular remappings of stereo spherical imaging. We rely on a recently presented differentiable DIBR ([3]), and additionally employ spherical weighting as an attention mechanism to address inconsistent gradient flows at the singularities. Finally, we also experiment with trinocular stereo placements and with infusing spherical spatial knowledge into the network implicity through the use of Coordinate Convolutions ([4]).
Code

Our training and testing code that can be used to reproduce our experiments can be found at the corresponding GitHub repository.
Different training scripts are available for each variant:
train_ud.pyfor vertical stereo (UD) trainingtrain_lr.pyfor horizontal stereo (LR) trainingtrain_tc.pyfor trinocular stereo (TC) training, using thephoto_ratioargument to train the different TC variants.train_sv.pyfor supervised (SV) training
The PyTorch implementation of the differentiable depth-image-based forward rendering (splatting), presented in [3] and originally implemented in TensorFlow, is also available.
Our evaluation script test.py also includes the adaptation of the metrics calculation to spherical data that includes spherical weighting and spiral sampling.
Pre-trained Models
Our PyTorch pre-trained models (corresponding to those reported in the paper) are available at our releases and contain these model variants:
- UD @ epoch 16
- TC8 @ epoch 16
- TC6 @ epoch 28
- TC4 @ epoch 17
- TC2 @ epoch 20
- LR @ epoch 18
- SV @ epoch 24
Data
The 360o stereo data used to train the self-supervised models are available here and are part of a larger dataset [1, 2] that contains rendered color images, depth and normal maps for each viewpoint in a trinocular setup.
Publication
Paper

Supplementary

Authors
Nikolaos Zioulis, Antonis Karakottas, Dimitris Zarpalas, Federico Alvarez and Petros Daras
Citation
If you use this code and/or data, please cite the following:
@inproceedings{zioulis2019spherical,
author = "Zioulis, Nikolaos and Karakottas, Antonis and Zarpalas, Dimitris and Alvarez, Federic and Daras, Petros",
title = "Spherical View Synthesis for Self-Supervised $360^o$ Depth Estimation",
booktitle = "International Conference on 3D Vision (3DV)",
month = "September",
year = "2019"
}
Acknowledgements
We thank the anonymous reviewers for helpful comments.
This project has received funding from the European Union’s Horizon 2020 research and innovation programme Hyper360 under grant agreement No 761934.
We would like to thank NVIDIA for supporting our research with the donation of a NVIDIA Titan Xp GPU through the NVIDIA GPU Grant Program.
![]()


Contact
Please direct any questions related to the code, models and dataset to nzioulis@iti.gr or post a GitHub issue.
References
[1] Zioulis, N.*, Karakottas, A.*, Zarpalas, D., and Daras, P. (2018). Omnidepth: Dense depth estimation for indoors spherical panoramas. In Proceedings of the European Conference on Computer Vision (ECCV).
[2] Karakottas, A., Zioulis, N., Samaras, S., Ataloglou, D., Gkitsas, V., Zarpalas, D., and Daras, P. (2019). 360o Surface Regression with a Hyper-sphere Loss. In Proceedings of the International Conference on 3D Vision (3DV).
[3] Tulsiani, S., Tucker, R., and Snavely, N. (2018). Layer-structured 3d scene inference via view synthesis. In Proceedings of the European Conference on Computer Vision (ECCV).
[4] Liu, R., Lehman, J., Molino, P., Such, F. P., Frank, E., Sergeev, A., and Yosinski, J. (2018). An intriguing failing of convolutional neural networks and the coordconv solution. In Advances in Neural Information Processing Systems (NIPS).