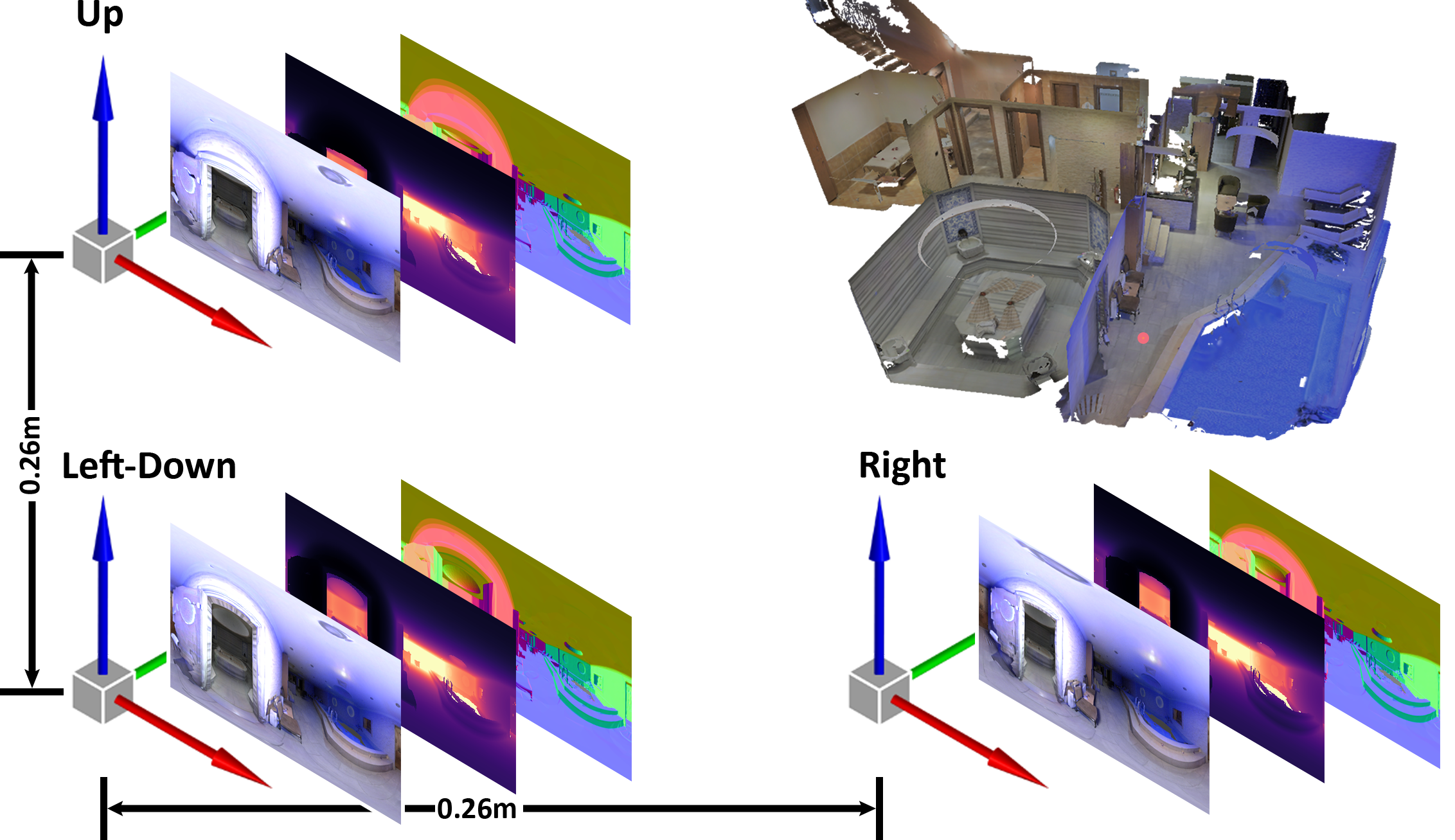
Overview
3D60 is a collective dataset generated in the context of various 360o vision research works [1], [2], [3]. It comprises multi-modal stereo renders of scenes from realistic and synthetic large-scale 3D datasets (Matterport3D [4], Stanford2D3D [5], SunCG [6]).
Motivation
Modern 3D vision advancements rely on data driven methods and thus, task specific annotated datasets. Especially for geometric inference tasks like depth and surface estimation, the collection of high quality data is very challenging, expensive and laborious. While considerable efforts have been made for traditional pinhole cameras, the same cannot be said for omnidirectional ones. Our 3D60 dataset fills a very important gap in data-driven spherical 3D vision and, more specifically, for monocular and stereo dense depth and surface estimation. We originate by exploiting the efforts made in providing synthetic and real scanned 3D datasets of interior spaces and re-using them via ray-tracing in order to generate high quality, densely annotated spherical panoramas.
News & Updates
- 11 Oct 2021: Major Update: An updated spherical depth estimation dataset (see here] has been released that fixes the lighting bias issue introduced during rendering and additionally contains:
- A solid baseline
- New metrics
- Additional data (GibsonV2)
- Higher resolution renders
- Distribution shifted splits
- 17 Oct 2019: Released a real domain only version of the dataset that does not include SunCG and contains all viewpoints and modalities in a single Zenodo repository. Check the download page for details
Description
Formats
We offer 3 different modalities as indicated below, with the corresponding data formats following and the invalid values (due to imperfect scanning, holes manifest during rendering) denoted in brackets.
| Image Type | Data Format | Invalid Value |
|---|---|---|
Color images |
.png |
gray, i.e. (64, 64, 64) |
Depth maps |
single channel, floating point .exr |
(inf) |
Normal maps |
3-channel (x, y, z), floating point .exr |
(0.0f, 0.0f, 0.0f) & (nan, nan, nan) |
Camera positions
Our spherical panoramas are generated using the provided camera poses for Matterport3D and Stanford2D3D, while for SunCG we render from the center of the bounding box of each building, which resulted to rendering artifacts and thus, a number of invalid renders.
Showcase



Usage
Download
Important: Please download the new Pano3D dataset which supersedes 3D60. Note that only 3D60 currently offers stereo renders and not Pano3D. If you need the stereo renders follow the striked-through process below, otherwise see the download data section of Pano3D.
We follow a two-step procedure to download the 3D60 dataset.
Note that only completing one step of the two (i.e. only filling out the form, or only requesting access from the Zenodo repositories) will not be enough to get access to the data. We will do our best to contact you in such cases and notify you to complete all steps as needed, but our mails may be lost (e.g. spam filters/folders).
The only exception to this, is if you have already filled in the form and need access to another Zenodo repository (for example you need extra viewpoint renders which are hosted on different Zenodo repositories), then you only need to fill in the Zenodo request but please, make sure to mention that the form has already been filled in so that we can verify it.
Each volume is broken down in several .zip files (2GB each) for more convenient downloading on low bandwidth connections. You need all the .zip archives of each volume in order to extract the containing files.
Data-splits:
We provide the train, validation and test-splits that we used for each related research task that used parts of the 3D60 dataset:
- Omnidepth: Dense Depth Estimation for Indoors Spherical Panoramas [1]
- Spherical View Synthesis for Self-Supervised 360o Depth Estimation [2]
- 360o Surface Regression with a Hyper-Sphere Loss [3]
However, we recommend using the common splits used in the latter two works ([2, 3]) as it is based on the official splits of the 3D datasets used to render the panoramas.
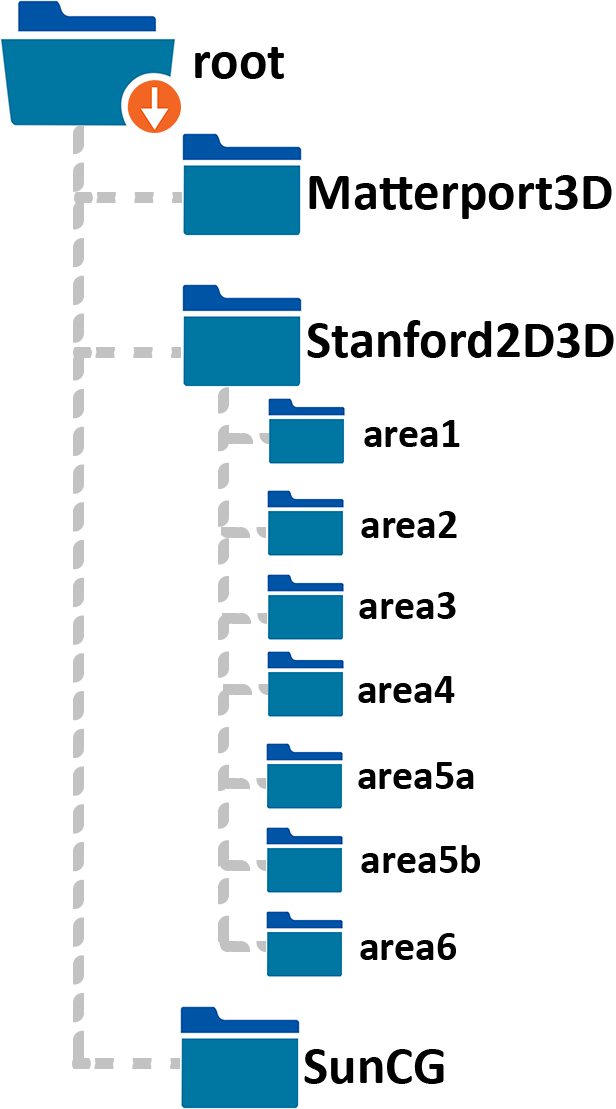
Organization
Tools
The 3D60 dataset is accompanied by code @ GitHub to:
- Load Data:
- Flexible PyTorch data loaders, configurable to load only specific parts, modalities or placements
- Longitudinal rotation (i.e. circular shift) data augmentation
- Script to visualize the 3D60 dataset using visdom, as an example of using the PyTorch data loaders
- Preparation Splits:
- Script to calculate the depth map statistics for each of its parts (i.e. distinct 3D datasets)
- Script to estimate ‘outlier’ renders whose depth distributions lie away or exceed certain thresholds
- Script to generate train/test/val splits for each part of the dataset (using each 3D dataset’s official splits), also ignoring ‘outliers’
Citations
The 3D60 data have been generated during distinct works and thus, depending on which subset (i.e. modalities and/or placements) are used, please cite the corresponding papers as follows:
- Depth maps:
@inproceedings{zioulis2018omnidepth, title={Omnidepth: Dense depth estimation for indoors spherical panoramas}, author={Zioulis, Nikolaos and Karakottas, Antonis and Zarpalas, Dimitrios and Daras, Petros}, booktitle={Proceedings of the European Conference on Computer Vision (ECCV)}, pages={448--465}, year={2018} } - Normals maps:
@inproceedings{karakottas2019360surface, author = "Karakottas, Antonis and Zioulis, Nikolaos and Samaras, Stamatis and Ataloglou, Dimitrios and Gkitsas, Vasileios and Zarpalas, Dimitrios and Daras, Petros", title = "360 Surface Regression with a Hyper-Sphere Loss", booktitle = "International Conference on 3D Vision", month = "September", year = "2019" } - Stereo pairs:
@inproceedings{zioulis2019spherical, author = "Zioulis, Nikolaos and Karakottas, Antonis and Zarpalas, Dimitris and Alvarez, Federic and Daras, Petros", title = "Spherical View Synthesis for Self-Supervised $360^o$ Depth Estimation", booktitle = "International Conference on 3D Vision (3DV)", month = "September", year = "2019" }
Contact
Please direct any questions related to the dataset and tools to nzioulis@iti.gr or post a GitHub issue.
Acknowledgements
This dataset has been generated within the context of the European Union’s Horizon 2020 research and innovation programme Hyper360 under grant agreement No 761934.
We would like to thank NVIDIA for supporting us with the donation of a NVIDIA Titan Xp GPU through the NVIDIA GPU Grant Program.
![]()


References
[1] Zioulis, N.*, Karakottas, A.*, Zarpalas, D., and Daras, P. (2018). Omnidepth: Dense depth estimation for indoors spherical panoramas. In Proceedings of the European Conference on Computer Vision (ECCV).
[2] Zioulis, N., Karakottas, A., Zarpalas, D., Alvarez, F., and Daras, P. (2019). Spherical View Synthesis for Self-Supervised 360o Depth Estimation. In Proceedings of the International Conference on 3D Vision (3DV).
[3] Karakottas, A., Zioulis, N., Samaras, S., Ataloglou, D., Gkitsas, V., Zarpalas, D., and Daras, P. (2019). 360o Surface Regression with a Hyper-sphere Loss. In Proceedings of the International Conference on 3D Vision (3DV).
[4] Chang, A., Dai, A., Funkhouser, T., Halber, M., Niessner, M., Savva, M., Song, S., Zeng, A. and Zhang, Y. (2017). Matterport3d: Learning from rgb-d data in indoor environments. In Proceedings of the International Conference on 3D Vision (3DV).
[5] Armeni, I., Sax, S., Zamir, A.R. and Savarese, S., 2017. Joint 2d-3d-semantic data for indoor scene understanding. arXiv preprint arXiv:1702.01105.
[6] Song, S., Yu, F., Zeng, A., Chang, A.X., Savva, M. and Funkhouser, T., 2017. Semantic scene completion from a single depth image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR).